Data–Pop Alliance has been conducting ongoing research on Big Data, climate change and environmental resilience. With funding from the UK’s Department for International Development (DfID), we published a synthesis report evaluating the opportunities, challenges and required steps for leveraging the new ecosystem of Big Data and its potential applications and implications for climate change and disaster resilience. This report will feed into the World Humanitarian Summit to be organized in Istanbul in May 2016.
This is the fourth in a series of companion pieces that offer insights from the synthesis report. The authors of the series attempt to go “beyond the buzz” to lay out what we actually know about Big Data’s existing utility for disaster science and for building practical resilience.
In the emerging field of data-driven resilience, one of the greatest challenges is simply getting everyone on the same page
Recent years have made it clear that data science's potential to bring rapid, large-scale changes to the global economy is only increasing. The spread of cheap, fast computing that accompanied and followed the first tech bubble of the 1990s has since paved the way for data analysis and data-driven services to remold sectors of the economy ranging from urban transportation to light manufacturing to agriculture, not to mention defining entirely new technological frontiers in industries such as social media, search, and logistics. While most of these advances continue to be led by the private sector, an increasingly large group of specialists, researchers, and first responders have begun to apply many of the same data techniques to more broadly humanitarian concerns, trying to lever recent advances in data science to increase the resilience of communities around the world to natural disasters.
As an Assistant Professor of Economics at the University of San Francisco who studies the costs of natural disasters, this comes as good news, and not a moment too soon. While last December's Paris Agreement may finally signal the beginning of coordinated global action to address climate change, every indicator suggests that even under optimistic scenarios natural hazard risk for much of the world will get worse this century before it gets better. Burgeoning populations with shrinking resource bases will only become more vulnerable to shocks like droughts and cyclones in coming years, a concern highlighted by the now-overwhelming evidence that climate variability can drive conflict. Increasing rates of urbanization in the developing world have shifted populations away from the risk of weather-driven fluctuations in agricultural livelihoods only to increase populations' exposure to urban climate risks such as deadly levels of air pollution and the risk of coastal flooding. Increasing climate variability and rising seas will in many cases only worsen underlying hazard risks. Estimates of these costs from applied economics and related fields increasingly suggests that they are massive, emphasizing the need to develop new technologies, institutions, and approaches for insulating humanity from the ravages of the natural world.
It is clear that data science can be a powerful tool in increasing society's resilience to these threats, and a recent overview of the field conducted by myself and an interdisciplinary team of researchers suggests enormous potential for such technology to make real differences in peoples' lives. Researchers have successfully demonstrated techniques that would allow first responders to use cell phone data records (CDRs) to observe population movements in real time to assess evacuation efforts, target relief, and better understand response dynamics. Mobile data platforms and social networks such as Twitter are increasingly used to provide citizens with a pathway to engage with governments, first-responders, and the scientific community, and have already made serious improvements in response quality. Advances in data techniques in natural and social science research meanwhile have brought extraordinary advances in risk warning and monitoring systems, allowing both recovery and prevention efforts to be directed where they'll do the most good.

Source: Flowminder, 2015
At first glance many of the proposed solutions in data-led resilience sound too good to be true, and one would be wise to be skeptical of audacious claims. There is a huge difference between first prototypes and workable products, and any new approach for using data to increase resilience will only be valuable if it's actually used. This means that big data approaches to increasing resilience need to directly address the various complex problems that pop up when one is relying on novel technologies that place high demands on human and organizational capital. New techniques are being developed that require unusually high degrees of technical proficiency, making multiple areas of expertise necessary to implement, or even interpret, data analysis. Mundane but nontrivial hurdles related to practically implementing any data driven project – where such large data will be stored and analyzed, how the data will be collected and transferred between stakeholders, how quickly analyses can be run – can easily sink an otherwise worthwhile project. Concerns about legal and ethical ramifications of using data technologies can make stakeholders, ranging from analysts and researchers to government officials to the public, withdraw from supporting projects or allowing data to be used. Differing regulatory frameworks only further compound the problem, exposing policy makers to difficult-to-navigate reputational and political risks when data projects are being discussed.
At the end of the day, the complex problems related to supporting, standardizing, and indeed increasing the "resilience" of these data-driven approaches themselves are the sort of large-scale coordination problems common when new technologies develop; one need only look back to the first widespread roll-out of internet technologies to find similar sets of problems. What is perhaps daunting is the unusually diffuse and public nature of disaster risk management. In the private sector, coordination problems can typically yield to the profit incentive; many of today's largest tech firms, such as Oracle, Microsoft, and Google can all in one way or another be viewed as having the seeds of their success in identifying opportunities to monetize standardization and coordination of information technologies so as to ease wide-spread and flexible use across many realms of society. Disaster risk, however, looks much more like a reinsurance market than a consumer product market, with infrequent large events dominating how firms make decisions. In this context it is unsurprising that coordination mechanisms are lacking; firms would need to be far-sighted, not driven by short-term profit, and willing to navigate the complex legal, governmental, and public relations aspects of disaster risk management and response in order to play their standard role.
While the disorganized and chaotic nature of progress in data-driven resilience can be disheartening, the good news is that there are huge social returns to be made by investing in coordination. Funding agencies, startup firms, and enthusiastic college graduates can all easily make the mistake of thinking that inventing exciting new technologies is the only way to help improve resilience, but one of the primary findings of our survey is that there are enormous opportunities to improve resilience simply by increasing coordination among actors. Centralizing and disseminating best practices, through conferences, workshops, working paper websites, newsletters, and the like can make it vastly easier for disconnected agents to quickly internalize solutions to common problems. Data philanthropy outreach, ranging from platform and infrastructure support to analysis and code development, can have enormous impacts, especially in settings with low prior technological capacity. Establishing common, open frameworks such as standard APIs for cell phone data could make coordination problems between different firms and research groups vastly less difficult to resolve. Indeed, some of the most exciting progress currently being made in data-driven resilience – from citizen-volunteer-led efforts to rapidly improve OpenStreetMap after disasters to the Humanitarian Data Exchange’s public clearinghouse of data sources – stems exactly from such efforts to coordinate actors.
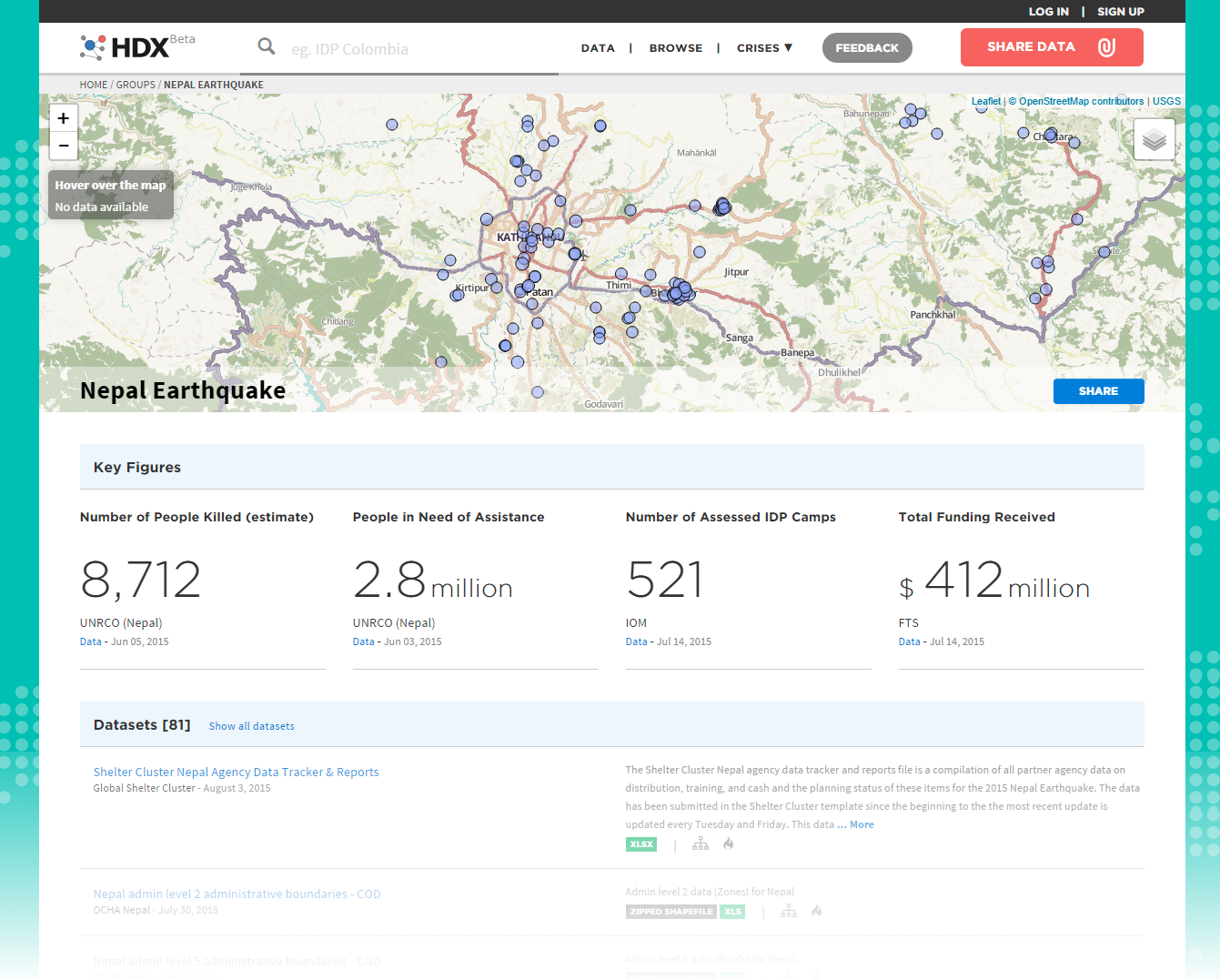
Source: Humanitarian Data Exchange, accessed August 2015
In sum, the field of data-driven resilience brings to mind author William Gibson's classic observation that the future is here, it's just not evenly distributed. Rectifying this - by focusing on distributing existing data technologies, ensuring that they work in context when needed, and helping establish best practices so that different actors need not reinvent the wheel - may not be as sexy as creating new analytic techniques or prototype technologies, but ultimately serve as important a role in ensuring that data techniques actually increase resilience as intended. In this light, the Paris Agreement's major achievement may ultimately be in simply establishing a common intent to coordinate among the world's governments. Perhaps now that this coordinating intent has been signaled, the many private sector firms, government agencies, and humanitarian actors that constitute the resilience space will be able to focus on working together to build the disaster response architecture that will defend humanity from the elements in the coming century.
Works cited


