LINKS WE LIKE #25
In commemoration of the international Zero Discrimination Day, and following the call to action from the president of the United Nations General Assembly Volkan Bozkir to “call out discrimination when we see it and advocate for a more just world”, this edition of LWL looks at issues of discrimination in artificial intelligence (AI) and data.
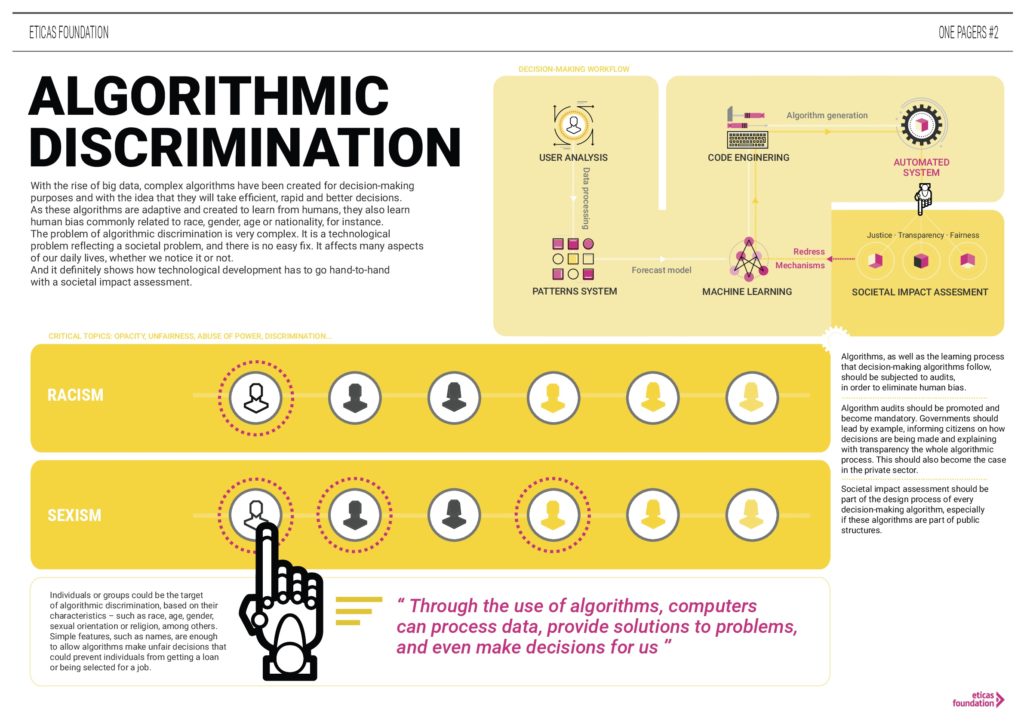
As AI and machine learning-implemented solutions grow more popular, experts grow more concerned about the human bias introduced inside the built algorithms. This situation has ignited a debate surrounding the ethical hurdles that societies will encounter as data scientists work towards programming the future. In fact, in the “2017 data scientist report”, AI specialist company CrowdFlower (acquired by Appen in 2019) asked 179 data scientists to list their top concerns in the field, and the results showed that 63% of the respondents are worried about “human bias/ prejudice programmed into machine learning” followed closely by the “impossibility of programming a commonly agreed upon moral code”. These concerns continue to be raised today, as discriminatory patterns reveal themselves in the field.
Ranging from AI systems used to determine student loans, and mortgages, to machine learning picture sets and google images, AI and data have been found to have a deeply discriminatory nature that is not limited to how it is used but instead to the intrinsic way in which it is built. How AI is structured and built matters because as Cathy O’Neil has argued in her book “Weapons of Math Destruction,” algorithms are opinions embedded in code; they are not objective, scientific or fair, but are rather the repetition of past practices. In this sense, as Andrew Burt – specialized lawyer in artificial intelligence and information security – suggests, discrimination as a result of using AI and data may not originate on conscious malicious intent (disparate treatment), but on disparate impact consequent of “neutral” variables acting as proxy’s for protected variables (i.e. gender and race).
To counter discrimination initiatives such as Incoding (proposed by Joy Buolamwini, an MIT graduate student and founder of the Algorithmic Justice League) have been set in place to fight what its creator calls the coded gaze. This mechanism factors fairness in machine learning algorithms, as it attempts to make “social change” a priority in data. Despite these initiatives, there is still much to be done. A continuous effort to combat the discriminatory behaviors that are embedded in our data and AI is needed. Moreover, we have to take into account that logarithms are not objective and that we need to question who is coding, how they are doing it and why, to get closer to a more just and transparent data ecosystem.
Read ahead to find excellent resources that will help you to better understand the nuances of intersection between discrimination, data and AI, and to reflect about the challenges and possible solutions posed by the leading experts on the field.

During the second episode of the “All tech is human” series in the Radical AI Podcast, authors and professors Safiya Noble and Meredith Broussard discuss how we can reduce discrimination present in data, as well as the algorithm bias that continues to perpetuate gender and racial stereotypes. Professor Noble argues that AI and data do not discriminate because of the way people use them, but rather because these technologies are designed in ways that foster oppression and social inequality. Furthermore, professor Broussard explains how tools like facial recognition are weaponized to discriminate against certain races and gender groups, and therefore the need to question the ways in which we use technology and reevaluate the notion that technology is always the best solution. Both professors make a call for holding algorithms accountable and for us to be conscious of how technology can promote discrimination. They also emphasize the importance of being actively involved in the conversation and decision-making processes.
Evidence from a new study conducted by Dominik Hangartner, Daniel Kopp and Michael Siegenthaler suggests that online recruitment platforms are discriminatory against immigrants, ethnic minorities and women. The authors developed a new method to monitor hiring discrimination by utilising supervised machine learning algorithms. Data was collected on 452,729 searches by 43,352 recruiters, as well as 17.4 million profiles that appeared in the search lists and 3.4 million profile views. The results reveal that recruiters using online recruitment platforms were up to 19 percent less likely to follow up with job seekers from immigrant and ethnic minority backgrounds than with equally qualified job seekers from the majority population. The analysis also reveals that women were seven per cent less likely to be contacted by recruiters when applying for roles in male-dominated professions. These findings suggest that unconscious biases have a strong impact on recruitment decisions especially when recruiters fall back on ‘intuitive decision-making’.
Analyzing the presence of biases in algorithms, Sendhil Mullainathan published a comprehensive article in the New York Times, where he explains why algorithmic bias is easier to correct for than human biases. A study conducted in 2019 unearthed the racial bias behind the algorithm used by the U.S. healthcare system, which led to determine that black patients had the same risk level than white patients when black patients were sicker. Mullainathan compares algorithmic with recruiter racial bias and argues that although it seems that the former is perceived as a massive problem, it is nevertheless easier to spot and fix than human bias. Humans, he says, are “inscrutable” in a way that algorithms are not. Since we tend to create explanations for our behaviour, only sophisticated and controlled experiments can detect our biases. Algorithms, instead, can be fed with the appropriate information to confirm their bias. The author also points out that it’s nearly impossible for humans to fix our biases, because it would imply changing “people’s hearts and minds”.
Mozilla fellow Deborah Raji outlines the extent of racism present in all sorts of datasets in a piece published by the MIT Technology Review in December 2020. A mere Google search for ‘healthy skin’ shows images of predominantly light-skinned women, whereas negative search terms linked to drug addiction or “big” facial features mostly reveals photos of dark-skinned individuals. Furthermore, she gives an example from Rashida Richerdson’s work found in her “Dirty Data, Bad Predictions” research paper. In it, Richardson pulled the alarm on the fact that data contribution duties are still entrusted to corrupt police officers who have proven track of discriminatory behavior. Based on this paper, Deborah does a test using GPT-2 created by OpenAI; not long after as she was giving prompts such as “a black woman is” she ended up getting questionable outputs centralised around “white rights” and a discussion about “non-white invaders”. This goes to show that policy-prediction tools developed with the help of such data are misleading and potentially harmful towards minorities.
The dilemma of racist and sexist algorithms is explored in an article published by Vox Media in February 2020, where Rebecca Heilweil explains that the term ‘Algorithm Bias’ refers to the fact that systems are biased depending on who built them, how they were developed and how they’re use, since these technologies often operate in a corporate black box. Further in the article, Rebecca quotes Lily Hu, a doctoral candidate at Harvard who states that “there is no guarantee that algorithms will perform fairly in the future because machines work on old data and on training data, not on new data which is not collected yet”. Therefore, it is almost impossible to find training data free of bias., The author emphasizes the need for new regulation laws for certain technologies such as facial recognition, noting having a legal mandate can support in one way or another the decrease of discrimination for companies building or using this tech.
Further Afield
Challenges for big data and discrimination
- Big Data & Issues & Opportunities: Discrimination
- Big Data and discrimination: perils, promises and solutions. A systematic review
- #BigData: Discrimination in data-supported decision making
- Who’s to blame when algorithms discriminate?
- The radical AI podcast: Episode 13: Data as Protest: Data for Black Lives with Yeshi Milner
- Big Data’s Dangerous New Era of Discrimination

Racism in AI and Data
- Race after technology
- Big Data and Racial Bias: Can That Ghost Be Removed from the Machine?
- Racist Data? Human Bias is Infecting AI Development
- Rise of the racist robots – how AI is learning all our worst impulses
- Race and America: why data matters
- Is an Algorithm Less Biased Than a Loan Officer?
- Yes, artificial intelligence can be racist
- Bias in AI: What it is, Types & Examples, How & Tools to fix it
Gender data and discrimination
- Gender Shades: Intersectional Phenotypic and DemographicEvaluation of Face Datasets and Gender Classifiers
- Artificial Intelligence Has a Problem With Gender and Racial Bias. Here’s How to Solve It
- Gender and Racial Bias in Cognitive AI
- AI Bias Could Put Women’s Lives At Risk – A Challenge for Regulators
- How AI bots and voice assistants reinforce gender bias
- Artificial intelligence and gender equality: key findings of UNESCO’s Global Dialogue
Books and documentaries on discrimination and data
- Algorithms of Oppression: How Search Engines Reinforce Racism
- Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor
- Artificial Unintelligence
- Coded bias





![M002 - Feature Blog Post [WEB]](https://datapopalliance.org/wp-content/uploads/2025/10/M002-Feature-Blog-Post-WEB.png)


