This is the second in a series of companion pieces that offer insights from the synthesis report. The authors of the series attempt to go “beyond the buzz” to lay out what we actually know about Big Data’s existing utility for disaster science and for building practical resilience.
As a social scientist studying how flows of information and knowledge affect societies' ability to adapt to environmental constraints, I see two things that could go wrong with the current craze for Big Data in the context of development, resilience and adaptation to climate change.
First, it could fail to improve the accountability and responsiveness of decision-makers (governments, corporations, organizations that wield resources and power) to citizens. In fact, Big Data could weaken relationships of accountability by making decision-makers more responsive to the subset of citizens that possess the human and financial means to engage with information technologies. Second, Big Data could grossly misrepresent people's experiences and aspirations. It could turn out to be yet another example of misguided technocratic hubris, of the kind denounced by political scientist James Scott in “Seeing Like a State: How Certain Schemes to Improve the Human Condition Have Failed.” In this book, Scott argues that plans based on scientific models and data often ignore local knowledge about complex interdependencies on the ground, and backfire as a result. For example, agronomists for a long time tried to transpose scientific agricultural practices developed for temperate climates to tropical countries. In doing so, they displaced the varied polycultures of farmers, which, he argues, were in fact much better adapted to the infertile soils in these regions.
Various observers have already noted these dangers. Some have pointed out that Big Data could exacerbate power disparities. With titles such as "Seeing Like a Database," others underscore the uncanny parallel between Scott's critique of bureaucracies' past embraces of data and the current rush towards big data solutions. But there is no point arguing about whether citizens, organizations and decision-makers should embrace big data – due to the digitization of society, these data flows are here to stay and grow. Instead I would argue that we have the ability to shape the new data creed so that it meets our shared need for making better individual and collective decisions. Since the use of data is always political, the pre-condition is that data becomes available and legible in ways that improve political processes from local to global scales. This seems possible because we now live in a world where vastly more people are educated, more governments are democratic, and over 90% of people across the world have access to information technologies. Furthermore, humanity has been warned already several times of the dangers of data-fueled technocratic decisions. Minds are thus poised to think about more inclusive ways of generating, diffusing, and understanding data. The report published by DfID in December 2015 provides several important examples of this.
An important aspect of Big Data is that it adds new channels of information to both citizens and governments. These channels carry information about members of society, the situations that are unfolding – such as disasters, inflation, social tensions, etc. – and how members of government react to these situations and citizens' needs. This has important implications.
First, decision-makers are better able to "see" their population. Enthusiasm about Big Data in development circles arises in large part from the perception that it can provide more comprehensive and more fine-grained data about populations than what is produced by statistical offices. For example, information about phone call patterns can provide good estimates of population density and income at a much finer spatial and temporal resolution than censuses do. These data source may also better account for people living in informal settlements. Since there can be no responsiveness if people are not even counted, the potential increase in state capacity thanks to Big Data is an important part of improving accountability.
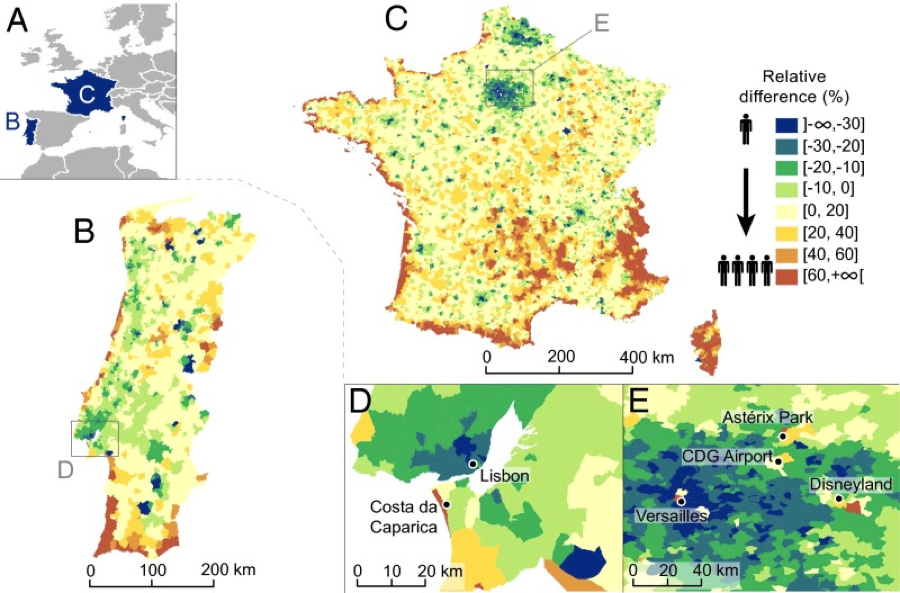
Seasonal changes in population distribution in Portugal and France, based on Call Detail Record (CDR) data.
Source: Deville et al. (2014).
Second, governments may become more legible to citizens. This is the critical second part of the accountability equation, which is much less often discussed. An example of how Big Data can help here is the Billion Prices Project at MIT, which monitors prices posted online to detect inflation trends and food insecurity. The project has shown that tapping into this passively emitted data (data arising spontaneously as a side-product of commercial activities) can reveal a very different situation than that depicted by official statistics or journalists. The impact of such information on societal resilience can be tremendous. In a 2000 study, Timothy Besley and Robin Burgess of the London School of Economics showed that over a period of 30 years, Indian state governments had been much more prone to distributing food to people suffering from food shortages in states with high levels of newspaper circulation and literacy, i.e. in areas where people were aware of the crisis and of what the government was doing about it. No quantitative research has yet studied the effect of digital technologies and Big Data flows on accountability in the context of disaster management, but this is something worth doing to learn how Big Data can contribute to resilience.
We see from this discussion that for Big Data to contribute to better political processes, it is fundamental that data (on the environment, communities, the economy, and governments) be open. Hence Big Data and the movement towards open data must go hand in hand. Important initiatives are underway, such as the Open Data for Resilience Initiative (OpenDRI). OpenDRI uses an open-source application, called Geonode, to help local actors process their existing data, engage communities in mapping data about their changing exposure to natural hazards and in participatory risk analysis. It is also fundamental that citizens have the means to be ingenious with that data. This means democratizing the access to analytical tools. Software such as InaSAFE can help create an interface to analyze the risk from disasters. Some engineers are working on an application to allow non-engineers to develop disaster-management applications themselves, from a simple visual user interface. Although little discussed thus far, it would also seem opportune to create partnerships with local universities, which could curate relevant datasets and engage in online and offline data analysis workshops to empower students in these universities to extract relevant knowledge.
The third consequence of new and more diverse information flows is that our perceptions are bound to become more robust, as they become less dependent on a narrow set of academic and administrative surveys generated according to predefined ideas (usually held by Western elites). In other words, Big Data flows can challenge people's thinking in more and perhaps different ways than do the results of traditional measurement and sampling. Relatedly, more people can contribute to shaping the information flows. For example, citizens can identify new sources of relevant Big Data (as in the Billion Prices project). Or people can actively generate data, as those who film encounters of citizens and police, documenting cases of abuse. Big Data and its flow through information technologies--unless hijacked and locked-up by bureaucracies and corporations--are more inclusive than data structures that are primarily generated and controlled by decision-makers.
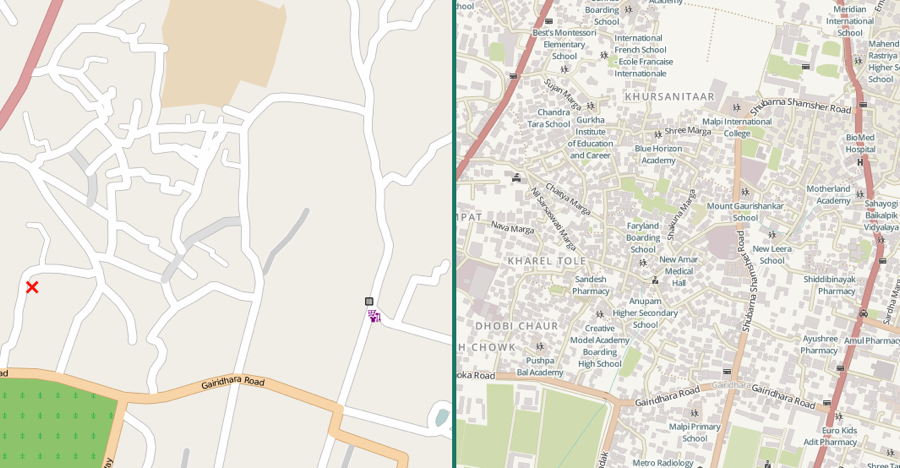
As a result, we may avoid the worse pitfalls highlighted by James Scott in "Seeing Like a State," namely mischaracterizing or simply ignoring ecological and social realities (including know-how and local knowledge) with the false confidence lent by science and data. In fact, the most sophisticated and most exciting Big Data projects in development and resilience work blend machine-generated data (from satellites, cell phones, internet activity and data-analytic algorithms) with local knowledge actively generated and communicated by citizens. For example, OpenStreetMap, a globally distributed organization with 1.5 million registered users and local groups in over 80 countries, is working to create a common open digital map of the world. Users edit a single database of maps remotely, digitizing the presence of roads, buildings, and so on, based on satellite images and their local knowledge. The Humanitarian OpenStreetMap Team (HOT) expands on this idea to create digital maps that are important for disaster preparedness or relief, again using local knowledge to locate vulnerable or damaged infrastructure. These organizations contribute to the formation of knowledge networks (rather than information products).
There is a risk that Big Data gets co-opted to reproduce an elitist and technocratic approach to solving public problems. We have learned from past experience that such an approach tends to weaken civil society and create more problems than it solves. Yet, there is also the promise – and, I would like to believe, the adequate conditions – for Big Data to give civil society new tools to engage in a more pluralist, robust, and resilient approach to development and environmental management.
Deville, P., Linard, C., Martin, S., Gilbert, M., Stevens, F. R., Gaughan, A. E., Blondel, V. D., & Tatem, A. J. (2014). Dynamic population mapping using mobile phone data. Proceedings of the National Academy of Sciences of the United States of America, 111(45), 15888–15893. https://doi.org/10.1073/pnas.1408439111Cite
Data-Pop Alliance. (2015). Big Data for Resilience: Realising the Benefits for Developing Countries [Synthesis report.]. Cite
Besley, T., & Burgess, R. (2000). Land Reform, Poverty Reduction, and Growth: Evidence from India. The Quarterly Journal of Economics, 115(2), 389–430. https://doi.org/10.1162/003355300554809Cite
Scott, J. C. (1999). Seeing like a State: How Certain Schemes to Improve the Human Condition Have Failed. Yale University Press. Cite
Besley, T., & Burgess, R. (2000). Land Reform, Poverty Reduction, and Growth: Evidence from India. The Quarterly Journal of Economics, 115(2), 389–430. http://doi.org/10.1162/003355300554809
Data-Pop Alliance. (2015). Big Data for Resilience: Realising the Benefits for Developing Countries (Synthesis report.).
Deville, P., Linard, C., Martin, S., Gilbert, M., Stevens, F. R., Gaughan, A. E., … Tatem, A. J. (2014). Dynamic population mapping using mobile phone data. Proceedings of the National Academy of Sciences of the United States of America, 111(45), 15888–15893. http://doi.org/10.1073/pnas.1408439111
Scott, J. C. (1999). Seeing like a State: How Certain Schemes to Improve the Human Condition Have Failed. New Haven: Yale University Press.